This year has been a wild ride. It has been filled with new experiences and added responsibilities. It was also a time for deep reflection. Issues that I have never considered before surfaced. These issues are philosophical in nature and have no straightforward answers. The provisional answers I have come up with are but a reflection of the stage of life I am currently in. I will address them through the course of this post.
The first half of the year was marked by the shift to Work From Home (WFH) arrangements. All across the world, people panicked in varying degrees. In response, many institutions initiated some form of support to be delivered to the public. Of which, MOOC providers such as Coursera offered quite a number of their Verified Certificates at no cost to interested individuals. Locally, NTUC LearningHub provided something similar as well. During this period, I completed 17 MOOCs (see here for a review of some of them).
Concurrently, I was on a training programme provided by my company. I had to manage this on top of my postgraduate studies. The first half of the year ended with the end of an exam paper I had to sit for. It was one of the toughest paper I had sat for (Machine Learning) and if not for an open-book online exam brought about by COVID, I definitely would have failed the paper.
The sedentary lifestyle that I have developed came back to bite me. In my routine health check-up, I came to learn that my cholesterol level has increased quite significantly. Following the report, I started combining exercising with gaming to make exercise more palatable. So far, it has been working out.
With my studies temporarily out of the way, the second half of the year was marked by new experiences. A friend invited me to join him in his business, with me handling all things tech-related. I got to learn a bit of hands-on stuff, but gaining traction for a new business is difficult, with COVID exacerbating it further.
The next two experiences were a serendipitous surprise. Crypto firms need all the manpower and help they can get. While WFH, I thought why not give volunteering at crypto firms a try. I volunteered at two firms. After a month or so, both firms were satisfied with my performance and offered me part-time employment (one firm even wanted me to quit my day job and work full-time with them!). I took up both offers, lol. Until now, I'm not sure how I'm going to manage a day job + 2 part-time jobs + postgraduate studies, but I'll try, lol. The worst case scenario would entail taking fewer modules each year and extending the duration of my postgraduate studies.
Another whammy came from the US Internal Revenue Service (IRS). One of those crypto firms was incorporated in the US. As a foreigner, I have to complete the dreaded W-8BEN form. Yes, it's that same form where the US gov eats 30% of your dividends from US stocks. As Singapore does not have a double taxation agreement with the US, this means that I'm taxed a second time (by SG gov) after the hefty 30% tax by the US gov. Oof.
For better or for worse, my involvement in the crypto space has resulted in increased exposure for me. With exposure comes unnecessary shit. There has been a case of scammers impersonating me and going around asking for crypto. There have also been attempts to hack my email as well. So stay safe and don't trust any random "Unintelligent Nerd" that attempts communication.
Other notable events in the second half of the year include getting rejected by a high quality girl, starting a new hobby which I have been procrastinating into getting into, and building software packages to pad my CV further.
I have also grown a thicker layer of skin this year (see here). Reflecting upon the underlying motivations of these critics made me learn quite a number of valuable life lessons:
An asymmetric risk/reward strategy for every generation
One characteristic that is common across quite a number of my critics is their selection of a strategy with an asymmetric risk/reward profile that prediposes them towards financial success in life. The specific strategy varies across generations. There is still a need to take risk to embark on a given strategy and how well the individual executes determines the extent of their financial success. I do not mean that this is a sure-win strategy; it just places the individual in a position that they are highly likely to win, and win big, relative to their generational peers who do not adopt this strategy.
I will not be specifying what these strategies are for the past generations. First, they will miscontrue that I am giving them zero credit for their success. This is not true. Their success is a function of their hard work, calculated risk-taking, execution, and riding on the coattails of long-term secular trends, with the secular trend being a huge contributor to their success. Second, they will bring up the rare exceptions who fail to achieve what they did. Again, this does not invalidate my point.
I think that it may be possible that the crypto/blockchain space will be the asymmetric risk/reward strategy for my generation. Increasing digitalization, growing adoption by enterprises, and the inflow of funds into the space are some indicators that the crypto/blockchain space is a nascent and growing industry.
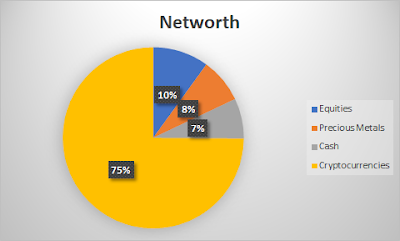
Take me as an example. Assuming all things equal (effort, time spent at work, etc), the financial rewards I receive from investing and working in the crypto space far exceeds that of my stock investments and my main job. Unfair? Somewhat. One unit of effort takes me much further than before.
When you live long enough, you become the villain?
In "The Dark Knight Rises", this was the infamous last words of Harvey Dent to Batman.
Success breeds confidence. There is weight and life experiences behind one's words.
This year has been an exceptionally good year for me and my multi-year efforts have finally bore fruit. My words pack more punch now. I have noticed my words have become a tinge bit more forceful. This is not ideal. I am slowly becoming the very critics whom I dislike.
It is not just me. There are others who share a similar dislike for some of these critics. The critics may have the real-world experience and success backing their words, but people dislike being talked down to. Especially so when the recipients did not ask for their advice.
I must learn to shut-up and talk only when asked.
Vicarious experiences doth not maketh a man
Similar to forceful words, name-dropping is equally grating on the ears. The curious thing about such a phenomenon is its lack of representativeness in constructing an accurate picture of reality.
There are two layers of analysis to this. First, is your network an accurate reflection of a given sector? Often, the information provided by a contact is idiosyncratic. The listener has to isolate the pertinent information and, if need be, supplement it with the inputs of other contacts from the same sector. Second, you are not your contact. Information-seeking conversations are but a condensed droplet of the speaker's life. It is much more fuzzy than we would like to admit.
Wallstreetplayboys made it quite clear that it is unwise to speak on the behalf of another industry just because we have contacts from that particular industry. What more about making decisions on semi-solid ground?
I have observed these conquerer types who, spurred on by their personal success, attempt to conquer adjacent fields. Some have blundered badly because they did not realize the playing field has changed.
On armchair philosophizing
For many bloggers, it is quite telling when they reach the tail-end of their investment journey. Their blog content shifts from money-making to philosophical reflections (No, I'm still a very long way from building a sufficient nest egg).
Sometimes, philosophizing is productive. It leads to the blogger using their financial firepower, social capital, and cultural capital to effect the Grecian arete into a particular activity in society, benefiting others and society in the process.
At other times, it is mere diagnosis. Pointing out the ills of society and throwing out normative statements ("what ought to be") when one has the power to effect a positive change is such a downer. The very people who could do something about "it" (whatever "it" represents) ends up not doing anything at all.
Is this a corollary of success?
I think so.
From what I observed, many end up pontificating, but the ones that got insulted by their readers are the ones who do not use their success productively. Readers aren't stupid. Readers can tell.
I've spent quite some time thinking about the possible solutions to unproductive armchair philosophizing. The provisional solution is to be a man of action, to create increasingly difficult challenges for oneself to surmount. When there is skin in the game and the stakes are high, one will be razor-sharp focused on the task at hand and be too busy to go around airing their partially-formed views to everyone.
During the necessary times of reflection, these individuals should challenge the subject matter experts of their choosing. This introduces humility and allows them to clash swords with the elites in the chosen field. Thus, they will finally get to know whether their reflections hold water or are they just a regular dilettante whose views aren't even worth listening to.
Generativity vs Stagnation
Psychology majors will be familiar with this heading. Erik Erikson, a developmental psychologist, proposed that at every life stage, humans are confronted with a particular developmental challenge that they must resolve.
For those in middle adulthood, they are confronted with the challenge of Generativity vs Stagnation. This challenge entails contributing to the younger generation or things that may outlast them. In other words, leaving a legacy. A failure to do so results in one being a statistic, a mere cog in society's machine.
I was particularly impressed with two online friends I got to know while working part-time in crypto. Because of their enthusiasm, teachability, and positive attitude, I successfully pushed for them to get part-time positions as well. I realized I liked seeing the young, driven, humble, and capable succeed.
Is this the uncle/boomer/lao kok kok in me speaking? I decline to comment further.
What I know is that I'm no armchair philosopher. I will push for the success of those whom I deemed worthy and will cheer alongside with them.
An Economic Loser
Life isn't all bright and cheery. There is a dark underbelly to it as well. Just as there are high-flying young shoots that require nurturing and time to grow, so are there dwellers of the river styx.
These denizens of the deep bring to mind Venkatesh Rao's Gervaise Principle. Simply put, Rao's premise is that there are 3 categories of individuals within a firm: The psychopath, the clueless, and the loser.
The psychopath is upper management. The stakes are all designed in their favour. Heads they win a lot; tails, they also win (just not as much). They are smart and cunning and they run circles around others.
Next, we have the loser, with loser being defined in economic terms. They are not paid in accordance to their contributions to the organization. If they were fairly paid for their efforts, the profit margins of the firm would shrink and there is less for the taking by the psychopaths and/or shareholders. Duh!
So what can the economic loser do? They can respond in one of three ways:
1). Eat snake. Do the bare minimum since the cards aren't in your favour and there's not much upside for you.
2). Work moar! Get promoted to middle management and manage the losers! Losers will laugh at you for doing this though. The responsibilities/stress growth > pay growth. ....And you are also indicating to the psychopaths that you don't know how to value yourself. You turned an already bad deal into an even worse deal. Hence, the "promotion" from the Loser group to the Clueless group.
3). You know your own self-worth, young psychopath-in-training. You have the competency and you refrain from bringing more to bear than what you are paid. Psychopaths recognize psychopaths and up you go on the corporate ladder!
I'm a Clueless-Loser (if there ever was such a group). Losers shoot me funny looks for trying too hard and I understand their point. It makes economical sense to do less, rather than do more. Doing more means getting a lot more shit and only a slight pay increase.
Psychopaths, on the other hand, require a complete shift in mindset and modus operandi. I suck at being cunning and ruthless. Oh well.
Comparison is a stealer of joy
One advantage that the Clueless have over the Loser is their improved financial status. The next question is to ask how much is enough?
This is a seemingly straightforward question but the answers to it are buried deep within our psyche. We need to know ourselves. We need to consciously and vehemently not compare with others on things that do not matter to us.
On-and-off, I have encountered the vile and ugly side in the SG Investment Blogosphere as well as Crypto Twitter.
One blogger cursed another blogger's entire family to get cancer because the latter outperformed the former in investment.
Another blogger said their spouse is inferior to another blogger's spouse.
A third blogger emphasized that it is better to underperform the market by having a loving family (Err.......False dichotomy.....)
A fourth blogger said that those who do not follow a particular investing strategy is a fake investor/fake trader/fake speculator.
A few gloated for the impending bankruptcy of growth investors (in 2020 where growth triumphs everything else).
The thing is.........all the above-mentioned are successful individuals. What's with the envy and mental gymnastics?
You then come to realize that worldly success and wealth are not a panacea for envy......
Contentment has to come from deep within.
Financial freedom from toxic people
In my more-naive days, I wanted to get to know more bloggers. I thought it was a good thing to have more friends.
Now? Not so. I have a core group of wisdom bloggers as friends and my cup overflows with their goodness. I don't need many friends; I only need a few really good ones.
One underrated thing that I learned this year is that Financial Freedom (or, more appropriately, financial security) allows one to choose who they want to mix with. I do not need to keep up pretences. I can actively choose to avoid the toxic people I mentioned in the previous section. This is implied power.
A gradual disappearance
A blogger friend highlighted that COVID has worsened inequality. The gulf between the rich and the poor has widened considerably. During this period, certain insensitive bloggers continue to harp about their glorious riches from growth stocks and cryptocurrencies. For personal safety, he deleted his own blog and erased his online trail and advised me to do the same.
As a privacy-focused individual, I agree with him. However, I also said to him that there are a number of individuals in the blogosphere who would make good friends. As a result, I would be staying, but remaining low-profile. Furthermore, I don't offend with clickbait blog titles, lol.
Anyway, my three jobs will take up much needed time for blogging. Thanks for reading friends! I'll still be around in the shadows. Cheers and let's rock it in 2021!